
Incident là gì? Định nghĩa và tầm quan trọng trong mọi tổ chức
Trong bối cảnh vận hành và kinh doanh hiện đại, thuật ngữ “incident” ngày càng trở nên quen thuộc. Nhưng incident là gì và tại sao việc hiểu rõ về nó lại quan trọng đến vậy? Bài viết này sẽ đi sâu vào định nghĩa, phân loại, quy trình xử lý hiệu quả và các chiến lược phòng ngừa, cập nhật những thông tin mới nhất đến năm 2026.
Một incident, hay còn gọi là sự cố, có thể được định nghĩa là một sự kiện không mong muốn, gây gián đoạn hoặc làm giảm chất lượng của dịch vụ công nghệ thông tin (CNTT) hoặc một hoạt động kinh doanh quan trọng. Nó khác với một “problem” (vấn đề) ở chỗ incident thường có tác động tức thời, yêu cầu giải pháp khẩn cấp để khôi phục hoạt động bình thường, trong khi problem là nguyên nhân gốc rễ của một hoặc nhiều incident.
Tầm quan trọng của việc quản lý incident hiệu quả không thể bị xem nhẹ. Một incident có thể dẫn đến:
- Gián đoạn dịch vụ nghiêm trọng: Ảnh hưởng trực tiếp đến khả năng cung cấp sản phẩm/dịch vụ cho khách hàng.
- Thiệt hại tài chính: Bao gồm chi phí khắc phục, mất doanh thu do gián đoạn, và các khoản phạt tiềm ẩn.
- Tổn hại danh tiếng: Mất lòng tin của khách hàng và đối tác.
- Rủi ro bảo mật: Các incident về an ninh có thể dẫn đến lộ lọt dữ liệu nhạy cảm.
Hiểu rõ incident là gì là bước đầu tiên để xây dựng một hệ thống quản lý sự cố mạnh mẽ, đảm bảo hoạt động kinh doanh diễn ra suôn sẻ và liên tục.

Phân loại Incident: Nhận diện và ưu tiên xử lý
Việc phân loại incident một cách rõ ràng giúp các tổ chức ưu tiên nguồn lực và phản ứng phù hợp. Các loại incident phổ biến bao gồm:
1. Incident về Dịch vụ CNTT (IT Service Incidents)
Đây là loại incident phổ biến nhất, liên quan trực tiếp đến các dịch vụ do bộ phận CNTT cung cấp. Chúng có thể bao gồm:
- Sự cố mạng: Mất kết nối internet, chậm mạng, không truy cập được máy chủ.
- Sự cố ứng dụng: Phần mềm bị treo, không khởi động được, lỗi chức năng.
- Sự cố phần cứng: Máy chủ, máy trạm, thiết bị ngoại vi bị hỏng.
- Sự cố truy cập: Người dùng không đăng nhập được vào hệ thống.
2. Incident về Bảo mật (Security Incidents)
Liên quan đến các hoạt động xâm phạm chính sách bảo mật, đe dọa tính bảo mật, toàn vẹn hoặc sẵn sàng của thông tin và hệ thống. Ví dụ:
- Tấn công Malware/Ransomware: Máy tính bị nhiễm virus, mã độc đòi tiền chuộc.
- Truy cập trái phép: Kẻ xấu đột nhập vào hệ thống.
- Lộ lọt dữ liệu: Thông tin nhạy cảm bị tiết lộ ra ngoài.
- Tấn công từ chối dịch vụ (DDoS): Hệ thống bị quá tải, không thể hoạt động.
3. Incident về Kinh doanh (Business Incidents)
Các sự kiện bất ngờ ảnh hưởng trực tiếp đến hoạt động kinh doanh cốt lõi, không nhất thiết liên quan đến CNTT nhưng có thể có tác động domino.
- Gián đoạn chuỗi cung ứng: Nhà cung cấp chính ngừng hoạt động.
- Thiên tai: Cháy, lũ lụt ảnh hưởng đến cơ sở hạ tầng.
- Lỗi quy trình nghiệp vụ: Sai sót trong quá trình sản xuất hoặc vận hành.
4. Incident về Sản phẩm/Dịch vụ (Product/Service Incidents)
Các lỗi hoặc trục trặc phát sinh từ chính sản phẩm hoặc dịch vụ mà tổ chức cung cấp cho khách hàng.
- Lỗi phần mềm trong sản phẩm: Khách hàng báo cáo lỗi khi sử dụng sản phẩm.
- Sự cố vận hành dịch vụ: Dịch vụ công cộng bị gián đoạn.
Việc phân loại dựa trên mức độ ảnh hưởng (Impact) và mức độ khẩn cấp (Urgency) giúp xác định mức độ ưu tiên (Priority) cho từng incident.
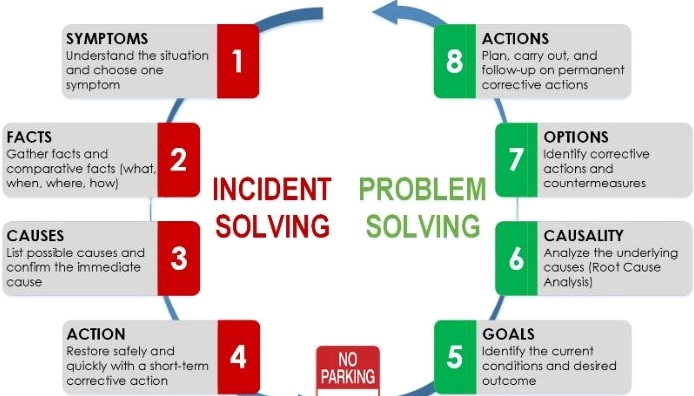
Quy trình xử lý Incident chuẩn mực: Từ báo cáo đến khắc phục
Một quy trình xử lý incident hiệu quả, thường tuân theo các bước được quy định trong các framework như ITIL, bao gồm:
Bước 1: Ghi nhận (Logging)
Mọi incident, dù nhỏ nhất, cần được ghi nhận lại. Thông tin cần thu thập bao gồm:
- Thời gian xảy ra.
- Người báo cáo và thông tin liên hệ.
- Mô tả chi tiết về sự cố.
- Hệ thống/dịch vụ bị ảnh hưởng.
- Mức độ ảnh hưởng ban đầu.
Bước 2: Phân loại và Ưu tiên (Categorization and Prioritization)
Dựa trên thông tin ghi nhận, incident được phân loại theo loại hình và mức độ ưu tiên (cao, trung bình, thấp) dựa trên tác động và mức độ khẩn cấp. Điều này giúp định hướng các bước xử lý tiếp theo.
Bước 3: Chẩn đoán ban đầu (Initial Diagnosis)
Đội ngũ hỗ trợ (thường là cấp 1) thực hiện các bước kiểm tra cơ bản để xác định nguyên nhân và tìm giải pháp khắc phục nhanh chóng (workaround) nếu có thể. Nếu vấn đề phức tạp hơn, incident sẽ được chuyển lên cấp hỗ trợ cao hơn.
Bước 4: Điều tra và Chẩn đoán (Investigation and Diagnosis)
Các chuyên gia (cấp 2, cấp 3) thực hiện phân tích sâu hơn để tìm ra nguyên nhân gốc rễ của incident. Họ có thể cần sử dụng các công cụ chẩn đoán chuyên dụng và phối hợp với các bộ phận liên quan.
Bước 5: Khắc phục và Phục hồi (Resolution and Recovery)
Sau khi tìm ra giải pháp, đội ngũ sẽ tiến hành triển khai để khắc phục incident và khôi phục dịch vụ/hoạt động về trạng thái bình thường. Sau khi khôi phục, cần xác nhận lại với người dùng rằng sự cố đã được giải quyết.
Bước 6: Đóng (Closure)
Khi incident đã được khắc phục hoàn toàn và người dùng xác nhận, incident sẽ được đóng lại. Thông tin chi tiết về nguyên nhân, giải pháp và bài học kinh nghiệm cần được ghi lại trong cơ sở dữ liệu sự cố.
Quản lý incident không chỉ dừng lại ở việc khắc phục. Việc phân tích các incident lặp đi lặp lại có thể giúp xác định các “problem” để giải quyết triệt để.

Chiến lược phòng ngừa Incident hiệu quả cho tương lai
Thay vì chỉ tập trung vào việc khắc phục, các tổ chức hiện đại hướng tới việc chủ động phòng ngừa incident xảy ra. Một số chiến lược quan trọng bao gồm:
1. Đầu tư vào hạ tầng ổn định và bảo mật
Sử dụng các thiết bị, phần mềm có chất lượng, được cập nhật thường xuyên và tuân thủ các tiêu chuẩn bảo mật. Việc này giúp giảm thiểu nguy cơ xảy ra sự cố do lỗi kỹ thuật hoặc tấn công.
2. Xây dựng quy trình làm việc chặt chẽ
Thiết lập các quy trình chuẩn cho việc triển khai thay đổi, quản lý cấu hình, và kiểm soát truy cập. Các thay đổi không được kiểm soát là một trong những nguyên nhân hàng đầu gây ra incident.
3. Đào tạo nhận thức cho nhân viên
Nâng cao nhận thức về an ninh mạng và các quy định an toàn thông tin cho toàn bộ nhân viên. Nhân viên là tuyến phòng thủ đầu tiên và cũng là mắt xích yếu nhất nếu không được trang bị kiến thức đầy đủ. Tham khảo thêm các kiến thức bổ ích tại tainhaccho.vn.
4. Thực hiện kiểm tra định kỳ và giám sát liên tục
Thường xuyên kiểm tra hệ thống, thực hiện đánh giá lỗ hổng bảo mật và giám sát hoạt động để phát hiện sớm các dấu hiệu bất thường. Các công cụ giám sát hiện đại có thể cảnh báo trước khi sự cố thực sự xảy ra.
5. Lập kế hoạch ứng phó sự cố (Incident Response Plan)
Chuẩn bị sẵn sàng các kế hoạch chi tiết cho từng loại incident tiềm ẩn. Kế hoạch này cần bao gồm các bước hành động cụ thể, phân công trách nhiệm rõ ràng và danh sách liên hệ khẩn cấp.
6. Học hỏi từ các Incident đã xảy ra
Phân tích nguyên nhân gốc rễ của các incident trong quá khứ và thực hiện các hành động khắc phục để ngăn chặn chúng tái diễn. Đây là quá trình cải tiến liên tục.
Kết luận
Hiểu rõ incident là gì không chỉ giúp các tổ chức phản ứng nhanh chóng và hiệu quả khi sự cố xảy ra, mà còn là nền tảng để xây dựng chiến lược phòng ngừa vững chắc. Bằng cách kết hợp quy trình xử lý chuẩn mực, phân loại khoa học và các biện pháp phòng ngừa chủ động, doanh nghiệp có thể giảm thiểu tối đa rủi ro, đảm bảo tính liên tục trong hoạt động và củng cố niềm tin của khách hàng trong bối cảnh cạnh tranh ngày càng gay gắt của năm 2026.